In this article we are going to share our experience working on a product solution for one of our customers, a corporation from the Silicon Valley. We were privileged to work on an Extract-Transform-Load (ETL) system which represents a Bridge between multiple APIs. In this article we are going to tell you our story and highlight issues you may face while developing a similar integration.
What is ETL? From the Wiki:
In computing, extract, transform, load (ETL) is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source(s). The term comes from the three basic steps needed: extracting (selecting and exporting) data from the source, transforming the way the data is represented to the form expected by the destination, and loading (reading or importing) the transformed data into the destination system.
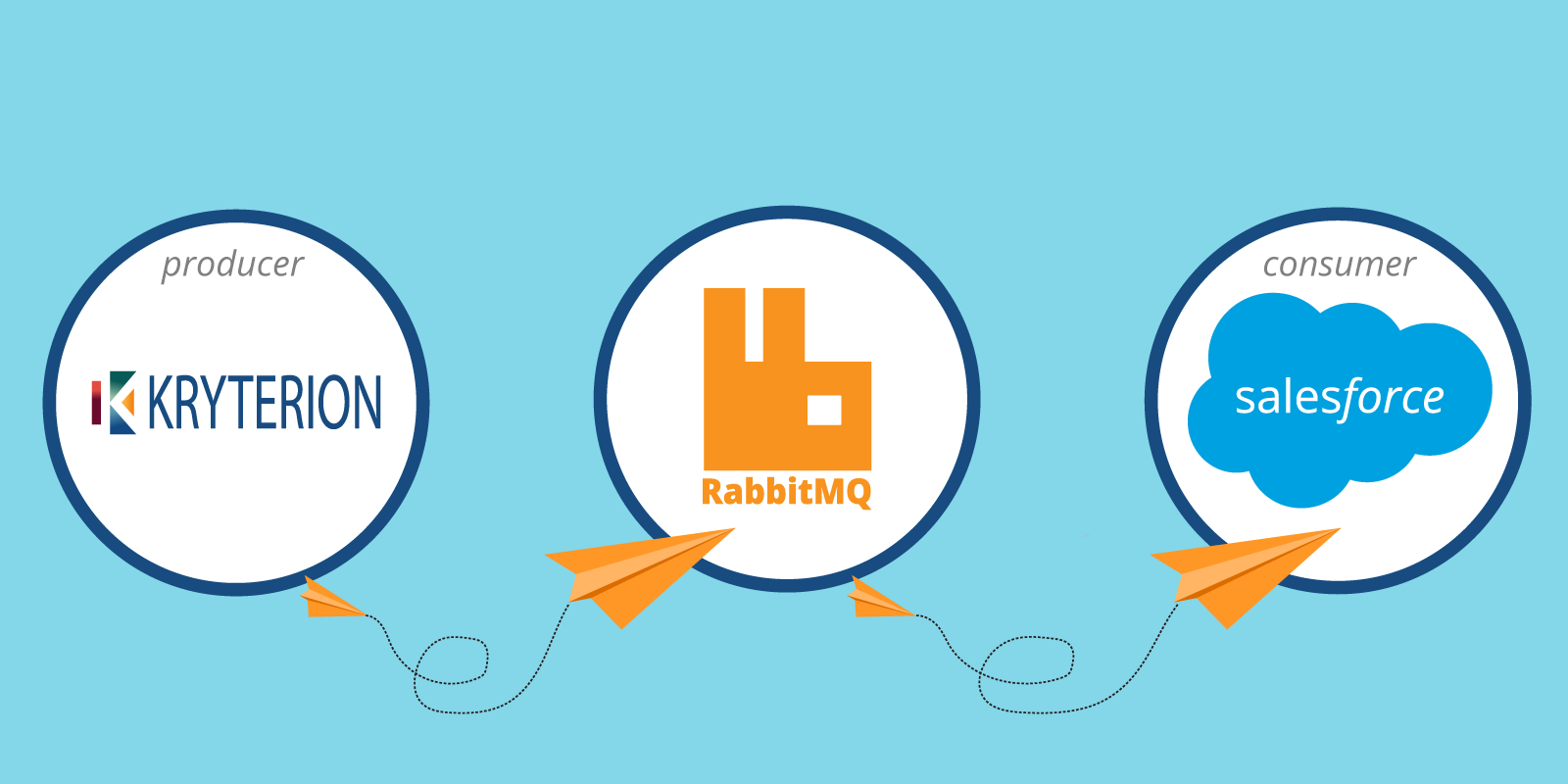
Our goal was to create a product that would join data from Kryterion to CRM Salesforce (SFDC), and it needed to be completely secure and reliable. Our customer was replacing inefficient software and they needed software that would serve them for many years to come.
The new software was needed because our customer was migrating from some other vendor to Kryterion. What is Kryterion? From the official website:
“Kryterion helps the most trusted and fastest growing companies, associations and education providers develop and deliver exams. Combine test delivery and proctoring solutions that meet your unique market testing needs. Easily deliver your exams worldwide through multiple delivery options from one central platform.
The most challenging task before us was to clearly understand what limitations the new APIs have and how those limitations (and potential lack of functionality) could be offset using our knowledge and experience to deliver a solution. First, we reviewed Kryterion API and compared it to the current functionality and new functional requirements. Kryterion has very specific underlying data structures and some limitations in place, so that probably make sense.
On the other hand, Salesforce is much simpler to work with, since their RESTful API is very well documented and pretty straightforward to work with.
The solution that we came up with was divided into two distinct routines: Producer and Consumer joined by the queuing mechanism – RabbitMQ. We picked RabbitMQ as it is the most well supported, open source message broker and proven to be very reliable software for the job to be done.
For production, we built a Stack using AWS Cloud Formation (CF) and AWS Elastic Beanstalk (EB) services and moved all sensitive credentials on to the AWS EB level to make it easy to re-configure the Stack when needed and keep it organized in one place. The whole Stack could be configured easily and securely within AWS Web Console or via AWS CLI.
For development we used Docker and Docker Compose to easily spin-up the Stack while developing locally. We shared RabbitMQ service between the Provider and Consumer and applied Adapter pattern to make it swappable.
Due to Kryterion’s limitations, we put a lot of design thought and consideration inside the Producer routine as it must respond well to interruptions and “bad” data. We designed this software for failure to be fault tolerant and have self-healing capabilities for both Producer and Consumer routines.
Also, we had to handle time zone issues, as people take tests around the globe and we had to make sure that all the tests were fetched properly, even if they were taken “in the past” because of the time zone difference. Stack’s excellent design allows for always-improving products rather than one-off projects; for example, field-mapping can be easily changed and redeployed in seconds, in case something changes on the Kryterion side. As well, the design allows for a data rollback should date re-processing be needed for some specific time-frame.
Additionally, we were able to add missing features, such as the number of attempts, and implemented it as a transactional record for our Consumer routine. Producer, on the other hand, transactionally handles data in batches with smart retries when needed, in case there was an interruption in the communication, or something else went wrong. In this fashion we achieved decentralized semi-governance. Consumer, on the other hand, encapsulates its own logic and handles messages reliably with smart retry capabilities, should Salesforce respond with an error.
What we would suggest for you, should you have such a need to build a similar solution? First of all, read API documentation carefully and make sure an API can handle what you are about to build. Secondly, as with any integration, plan for a slow and unreliable network, bad data and interruptions, and design for fault-tolerance. Another piece of good advice: keep an eye on data consistency and integrity because sometimes APIs do not serve you what its documentation says.
We are proud that our team at Konstankino was able to ship this product to production, and it now processes massive amount of data daily. As a result, our customer can concentrate on their business and not operational issues.
We describe this software as a product because a product is not a program, and a program is not necessarily a product. A product is a well-designed solution to a specific issue that works reliably well in almost any condition, treating software as an always-improving product. When you ship a product, you know that it must just work out of the box, with a “batteries included” mindset. For us, our end-user was not our customer, our end-users were those people who will be taking tests in Kryterion and expecting those tests to appear in the SFDC. In other words, we were designing this software not for IT departments but for the thousands of people who will be using it.
We were privileged and pleased to work on this software, and we think it shows a lot of our strengths and demonstrates our insistence on conforming to our own and our customer’s quality standards.